研究
モバイル・ユビキタスコンピューティングをはじめとする社会情報基盤の高度化や多様な情報ビジネス・情報応用の展開に伴い,人類がこれまで体験したことのない超大規模なデータを扱うビッグデータ時代が到来しています.地球規模でビッグデータがリアルタイムで飛び交う中で,必要なデータをいかに入手し有効な情報として活用するかが真に重要となっています.当研究グループでは,データ工学を中心としたアプローチにより,次世代情報化社会の基盤構築を目指した各種研究開発を推進しています.
1)情報統合基盤技術
-
指定イベント駆動型ストリーム処理
ストリームデータの増加に伴い,データ連携においてストリームデータの扱いが重要な課題となってきている.ストリームデータ処理を行うストリーム処理エンジン(SPE)は,複数のストリーム情報源からデータが到着するたびに,予め指定された問合せを処理し結果を出力する.これまで様々なシステムが研究開発されてきたが,本研究では様々なデータ連携応用の基盤として利活用可能であり,かつ,JSONの半構造データストリームを扱うことが可能なシステム技術の研究開発を行なっている.
ユーザの意図として特定のストリーム情報源からデータが到着した時にのみ問合せ処理を実行したいという状況がある.例えば,あるニュースが発生した際に,関連するツイートを収集するという状況である.本研究では,このようなイベント駆動型ストリーム処理に注目し,イベント駆動型ストリーム処理を効率的に行う問合せ処理手法を開発した.
イベント駆動型ストリーム処理では,対象となるストリーム情報源とイベントの有効期間が指定される.提案処理手法では,対象となるストリーム情報源からデータが到達してから有効期間の間だけ問合せ処理を実行することで,効率的にイベント駆動型ストリーム処理を行う.より具体的には,イベント駆動時に必要なデータだけを保持し,利用するためのスマートウィンドウ方式を提案することで,効率的なイベント駆動型ストリーム処理を実現する.さらに,様々なストリーム処理要求が複数登録された場合でも,それらに共通する部分的処理結果を共有し効率的な処理を行なう手法についても検討を行った.
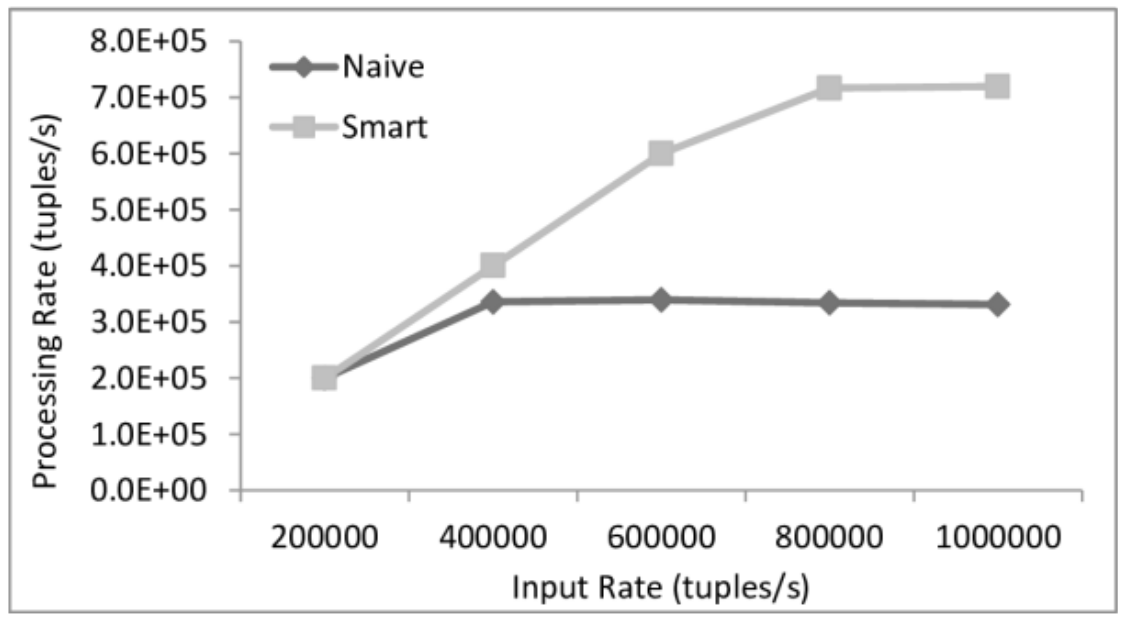
提案手法の有効性を検証するために,スマートウィンドウ方式を使う場合とそうでない場合の処理性能の比較を行った.実験では,ストリーム情報源から送信されるデータ数を増加させた時に,どの程度のデータが処理できるかを検証した.実験結果を図に示す.図から従来手法(Naive)よりも多くのデータを効率的に処理できていることが確認できた.
-
ストリームOLAP基盤
センサデータやマイクロブログ等,連続的に生成され,配信されるようなストリームデータが増加している.ストリームデータを処理する基盤としてストリーム処理エンジン (SPE) が多数開発されている.このようなSPEには,STREAM,Storm,Borealisなどが挙げられる.SPEにSQLのような問合せであるCQLで書かれた問合せを登録することで,ストリームデータに対して連続的な問合せを行うことができる.
このストリームデータに対し,より多角的なデータの傾向などを分析したいというニーズが高まっている.そのような多角的なデータ分析の代表例として,OLAP処理がある.ストリームデータに対してOLAP処理を行う研究として,例えばJiawei HanらはStream Cubeと呼ばれるアーキテクチャを提案している.しかし,この手法はSPEの利用を想定しておらず,一部の問合せの結果を返すことができないなどの制約が存在する.
OLAP処理では,分析対象のデータの次元や次元内の階層の全ての組合せを考える.StreamOLAPを実現する最も単純な方法として,これらすべての組み合わせに対応したCQLの問合せをSPEに連続的問合せとして登録し,これらの結果から,OLAP問合せの結果を実体化しておくことが考えられる.しかし一般には,全組み合わせ数は膨大な数になるため,すべての連続的問合せをSPEに登録することは処理性能上難しい.また,これらの全ての結果を実体化することもメモリ制約から現実的ではない.さらに,必ずしも全ての組み合わせに対応する問合せの結果を実体化する必要はなく,ユーザ要求に応じて導出すれば十分である.
これらの課題を解決するために本研究では,SPEとOLAPエンジンからなるストリームデータに対するOLAP処理(以下,StreamOLAP)のためのアーキテクチャを提案した.また,コストモデルに基づいた最適化アルゴリズムを開発した.提案アルゴリズムは,与えられたメモリ制約の範囲内で処理コストの最適化を図るアルゴリズムである.より具体的には,全OLAP問合せを,SPEに連続的問合せとして登録し集約結果を実体化しておく問合せ (Registered query)と,ユーザ要求に応じて実体化した問合せ結果から自身の集約結果を導く問合せ (On-demand Query) の二種類に分類する.
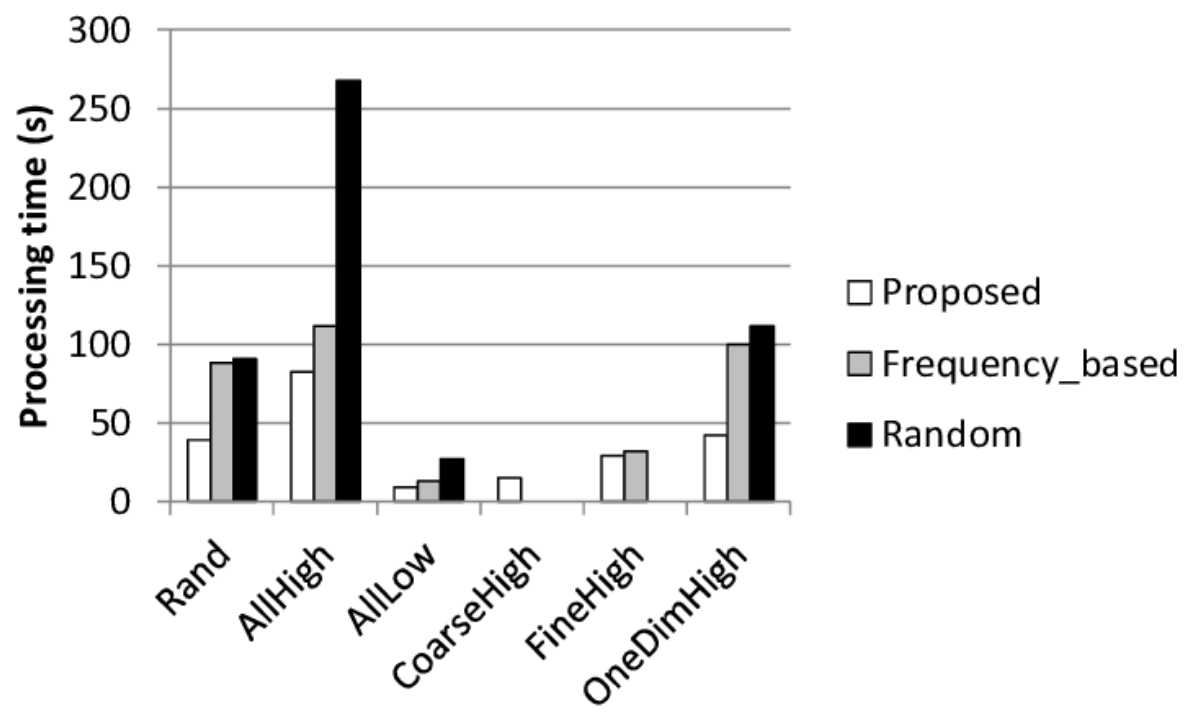
実施した実験について述べる.本実験ではStreamOLAPにかかる処理時間の測定を行う.提案アーキテクチャにはSPEとして商用のuCosminexus Stream Data Platformを使用し,OLAPエンジンは我々が実装した.本実験にはデータベースのベンチマークの一つであるTPC-Hで用いるデータセットを本実験用に加工したものを用いる.提案手法と以下の二つのベースラインとを比較する.
-
Frequency-based: Registered queryを各問い合わせの参照頻度が高い順に選ぶ.
-
Random: Registered queryをランダムに選ぶ.
実験結果を図に示す.x軸は六通りの参照頻度の与え方を示している.y軸は処理時間を示している.これらの結果から,提案手法がベースラインより処理時間が短いことが分かる.
-
-
クラウド上のプライバシー保護データベース
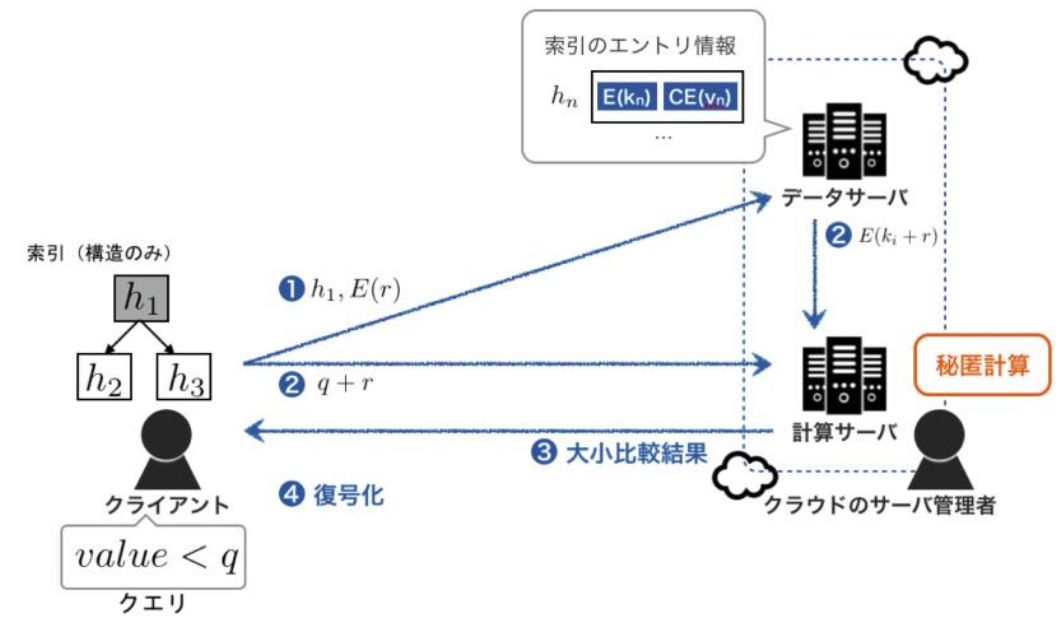
本研究では,データプライバシ及びクエリプライバシを保護することのできるクラウド上のデータ管理システムの実現を目指す。より実用的かつ安全性の高いシステムを目指し,データベース索引を検索可能暗号で暗号化し索引値を秘匿したまま探索する.索引を用いるためすべてのデータをスキャンすることなく効率的に解を求めることができ,索引値,クエリ及びデータも暗号化したまま計算を行うため安全性を保証することができる.ただし索引をサーバに保存すると索引構造から順序関係が明らかになる.そこで我々は索引を構造情報とエントリに分解し,構造を持たないエントリ集合はサーバに,構造情報を検索者が所有する手法を提案している.また、本探索手法ではクライアントとサーバ間の通信回数が計算に影響すること踏まえ適切な索引を求めると,計算サーバが1台の場合はノードのエントリ数は1, つまり二分探索が最も効率が良いことがわかった.本研究と同様にデータベース索(B+-tree, R-tree)を暗号化したまま探索するHuらの手法と計算速度を比較したところ,データ数100,000の場合Huらの手法では84秒かかったのに対し,我々の手法では0.27秒と大幅に速いことが明らかになり,またHuらの手法がもつ脆弱性も本提案手法では解決されることがわかった.
2)データマイニング・知識発見技術
-
不確実データに対する外れ値検出
データや応用の多様化や,各種センサデバイスの発達に伴い,不確実性を伴うデータ処理に対する要求が高まっている.例えば,GPSによる位置情報には,本質的に誤差が含まれており,その誤差を考慮した処理が求められる.一方,通常のデータからは著しく異なるデータ(外れ値)を検出する外れ値検出がさまざまな応用で利用されている.不確実データに対して外れ値検出を行う場合,データの不確実性を考慮した上で検出処理を行うことが望ましい.
本研究では,ガウス分布に従う不確実性を持つデータに対する距離に基づく外れ値検出手法について検討した.特に,外れ値の度合いが大きいものからk件の外れ値を検出するトップk外れ値検出のアルゴリズムを考案しその有効性を示した.厳密な外れ値度を計算する上ではガウス分布を考慮した距離計算が必要であるが,それには多大な計算コストが伴う.そこで,提案手法では,外れ値候補オブジェクトの外れ値度の上限と下限を求め,それに基づきトップk外れ値に入り得るかを判定するkとで,計算コストを大幅に削減する.
またさらに,静的なデータ集合ではなく,データがストリームとして系列的に到着する場合を想定し,それに対応した差分計算に基づく効率的な連続的外れ値検出の手法についても検討を行った.
-
Twitterユーザの居住地推定

ソーシャルメディアを通じて実世界を知ろうとする研究が注目を集めている.例えば,地震や台風などの実世界イベントの検知,インフルエンザなどの感染症の分析,災害の分析などはその代表例である.実世界のどこでこのような現象が起こっているのかを知ることは重要であり,それを知るためにはソーシャルメディアユーザの居住地情報の推定が重要である.
本研究の着眼点は,時間的に変化する「ローカルワード」の存在である.ローカルワードとは,特定の地域に密接に関連する単語のことである.例えば,「筑波山」や「つくばエクスプレス」などはつくば市に強く関連すると考えられるため,ローカルワードである.これらのローカルワードの中には,ある特定の期間においてのみローカルワードたり得るものが存在する.例えば,「地震」という単語は通常時は特定の地域と関連しているとは言えないが,地域Aで地震が発生した際には地域Aにおけるローカルワードであるとみなすことができる.本研究で提案した居住地推定手法は,これらの時間的に変化するローカルワードを逐次抽出し,ローカルワードを投稿したユーザはそれに関連する地域に住んでいるという推定を行う.
本実験ではTwitterから収集した201,570のTwitterユーザの情報と,それぞれのユーザが投稿した直近200の投稿を用いて6つの既存手法と比較した.また,ユーザ間の友人関係を表すソーシャルグラフを用いる既存手法を実行するため,ユーザ間の友人関係も合わせて収集した.実験結果を図に示す.横軸は推定結果と実際の居住地との誤差距離を表し,縦軸は誤差距離が対応するx軸の値以下であるユーザの割合(正解率)を表している.各線がそれぞれの推定手法の結果を表している.OLIMが提案手法である.時間的な要因を考慮しない既存手法と比較して,提案手法がより効果的に居住地の推定をしていることを示している.
-
一般のネットワークにおけるノード分類
ネットワークにおけるノード分類とは,一部のノードにラベルが付与されたネットワークが与えられた時,ラベルが付与されていないノードのラベルを推定する問題である.例えば,ソーシャルメディアにおけるユーザ間の関係を表したネットワークを入力とし,ユーザの居住地,年齢,性別などのラベルを推定する問題がこれに当たる.他にも様々な問題に対して応用可能であるため,ノード分類は幅広く研究されている問題である.
ノード分類問題における一つの課題として,ノード間のラベル相関の多様性がある.ラベル相関とは,「隣接ノードは同じラベルを持ちやすい」という傾向や,逆に「隣接ノードは異なるラベルを持ちやすい」というような傾向のことである.例えば,ソーシャルグラフ上において隣接ノード同士は居住地が近い傾向にあると言われているが,Pokecと呼ばれるソーシャルメディア上では隣接ノードは性別が異なる傾向にあることが分かっている.このように,実世界のネットワーク上においてはラベル相関は様々である.
本研究では任意のラベル相関に適用可能であり,かつパラメータの設定を必要としないノード分類アルゴリズムを提案する.これにより,実世界に存在する様々なネットワークにおけるメタデータをシームレスに推定することが可能になる.本研究の着眼点は,個々のノードごとにラベル相関を(自動的に)決定するという点である.あるノードAに着目した時,Aの隣接ノード集合の大部分がラベルLを持っていたとする.このとき,Aの隣接ノードのうち,ラベルが付与されていないノードも同様にラベルLを持つ可能性が高いという推定を行う.シンプルな仮定ではあるが,これによりラベル相関に関する事前知識(パラメータ)を必要とせず様々なラベル相関を持つネットワークに適用することが可能となる.
本実験では様々なラベル相関を持つ5つのネットワークに対してノード分類を行った.比較した既存アルゴリズムは前述のLabel Propagation (LP) とBelief Propagation (BP) である.実験結果を図に示す.5つのプロットはそれぞれのデータセットに対する結果であり,OMNI-Propは提案アルゴリズムの名前である.各点は確信度が大きい上位p%(x軸)のノードに対する分類精度(y軸)を表している.図によると,ほぼすべての場合において提案手法がもっとも高い精度を示していることが分かる.

-
Twitterにおけるフォロー要因推定
Twitterでは,ユーザは他のユーザをフォローし,他のユーザの投稿(ツイート)を受信・閲読することができる.一般に,ユーザは他のユーザの投稿内容や,あるいは他のユーザ自身に興味が有るため,フォローすると考えられる.したがって,フォロー要因を推定することができればユーザの興味などの推定につながると考えられる.
本研究の着眼点は,ユーザからユーザへのフォローという行動に加えて,ユーザからユーザへのタグ付けという行動を合わせて用いる点である.Twitterユーザは,リストという機能を用いて他のユーザをタグ付けすることができる.例えば,テニスに興味のあるユーザが「テニス」という名前のリストを作り,テニスに関連する他のユーザを作成したリストに登録することがある.ユーザ間のタグ付け関係を用いることで,あるユーザがなぜ他のユーザをフォローしたかという要因がタグという明示された形で示されるメリットがある.
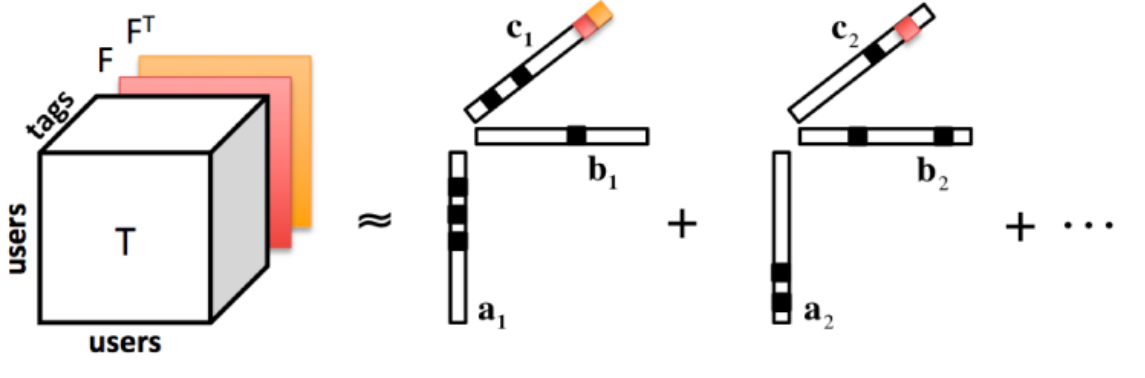
提案アルゴリズムの概要を図に示す.本研究で提案するアルゴリズムは,ユーザ間のフォロー関係を行列,ユーザ間のタグ付け関係をテンソルとして表現し,テンソル分解を用いて潜在的なフォロー要因を推定する.フォロー関係はフォローするユーザIDとフォローされるユーザIDの2つ組であり,タグ付け関係はタグ付けをしたユーザID,タグ付けをされたユーザID,タグIDの3つ組である.図中の行列FTはFの転置である.出力はそれぞれの次元に対応した3つのベクトルを一組とするベクトル集合の集合である.各ベクトル集合はそれぞれあるトピック(テニスや科学など)に対応しており,ユーザが他のユーザをフォローする要因を表している.ベクトルcの非ゼロ要素は対応するベクトル集合のトピックを表し,ベクトルaおよびbの非ゼロ要素は対応するトピックを要因としてフォロー関係となっているユーザのIDを表す.
実験ではTwitterから収集した147,541ユーザ間のすべてのフォロー関係1,821,432およびすべてのタグ付け関係179,868を用いた.様々なトピックが見られたが,結果の例としてHockeyおよびWritersの2つのトピックについて述べる.Hockeyトピックでは少数の有名ユーザ(プロホッケー選手など)をこのトピックに興味を持つ多数のユーザが単方向的にフォローするという構造になっていた.一方,Writersトピックではこの分野に関心を持つユーザが互いにフォローし合うという構造になっていた.このように実験結果を定性的に評価したところ,提案アルゴリズムはユーザ間のフォロー要因を適当に推定できていることが示された.
-
異種ソーシャルメディアにおけるユーザ行動分析
多くのソーシャルメディアでは,ユーザは様々なリソース(写真,動画,URL,他のユーザなど)をタグ付けすることができる.例えば,Flickrと呼ばれる写真共有ソーシャルメディアでは,ユーザは自らが投稿した写真や他のユーザの写真に対してタグ付けをすることが可能である.これらのタグはリソースのメタデータであると考えられるため,複数のソーシャルメディアデータを統合利用する際に重要な役割を担う.そこで本研究ではユーザのタグ付け行動を複数のソーシャルメディアにわたって分析し,そこに潜む様々なパターンの抽出を行った.
本研究では主にTwitterにおける「ユーザがユーザをタグ付けする」という側面に着目する.これは他のソーシャルメディアにはない特徴であるため,ユーザのタグ付け行動についてより深く考察するために重要である.本研究では具体的に以下の3つの質問に答える:(質問1)複数のソーシャルメディア(Flickr, Delicious, Twitter)において,ユーザのタグ付け行動に共通するパターン,もしくは相違点はあるか.(質問2)Twitterユーザはどの程度相互にタグ付けをするか.(質問3)Twitterにおいてタグ付けとフォロー関係との間にはどのような違いがあるか.
実施した実験について述べる.本実験ではTwitter,Flickr,およびDeliciousから収集した1,000万スケールのタグ付けデータを用いた.得られた結果は以下の通り.
- Twitterユーザは他のユーザをカテゴリ分けするためにタグを利用しているが,FlickrおよびDeliciousではユーザをカテゴリ分けするだけでなく,詳細を記述するためにタグを利用している(質問1).
- DeliciousおよびTwitterにおいては多くのユーザが同一のリソースに対してタグ付けをする傾向にあるが,Flickrではそれぞれのユーザが異なるリソースに対してタグ付けをする傾向にある(質問1).
- Twitterユーザが他のユーザからタグ付けされた際に,タグ付けを返す確率は,他のユーザからタグ付けをされた回数の対数に比例する(質問2).
- Twitterにおけるユーザ間のフォロー関係とタグ付け関係は約6割重複している(質問3).
- Twitterにおけるタグはその使用傾向からSubscriptionタグとFriendshipタグの二種類に分けることができる.前者は一般ユーザから有名ユーザへのタグであり,後者は一般ユーザ間,主に友人間(相互フォローしているユーザ間)において利用されるタグである(質問3).
これらの観察から,ソーシャルメディアにおけるメタデータ推定,および異種ソーシャルメディアデータの統合利用に関する考察が深まるものと考えられる.
-
GPUを用いた不確実トランザクションデータに対する確率的頻出アイテム集合マイニング
不確実性を含む大量のデータの処理のために,不確実データベースの研究が広く行なわれている.不確実データベースに対して,頻出アイテム集合マイニングを行なう手法がいくつか提案されているが,処理速度が遅いという問題がある.一方,GPU (Graphics Processing Unit) を用いた GPGPU (General Purpose computation on GPU)という手法が,高性能計算の分野で注目されている.GPGPUは,元々はグラフィック処理のための演算装置であるGPU を,その高い並列度をいかして汎用的な計算に利用するものである.
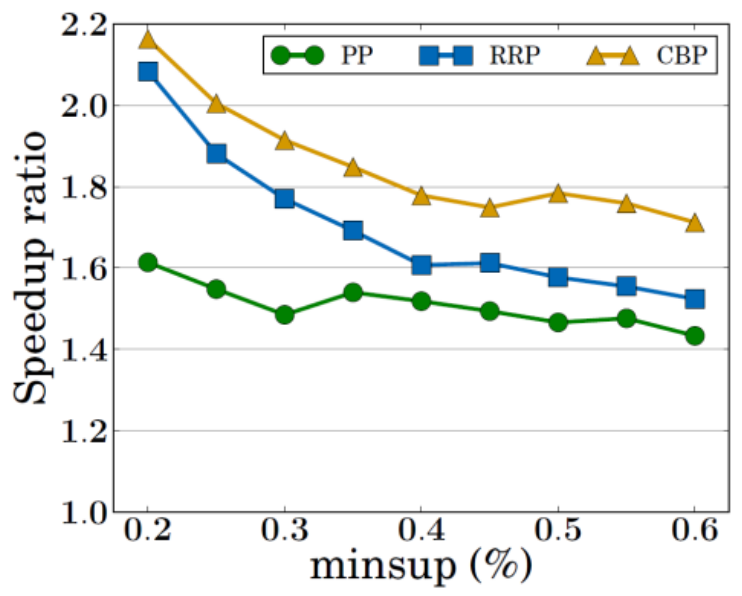
我々はこれまで単一GPUを用いた不確実データベースに対する頻出アイテム集合マイニングの高速化のための手法を提案してきた.本研究では単一GPUに対する手法をベースに,複数のGPUを搭載した複数のノードから構成されるクラスタ環境において,同様の処理を行う手法を提案する.複数GPUを用いる利点として,GPUの増加による並列度の向上がある.また,GPUのメモリはそれほど大きくないが,複数GPUにすることで利用可能なメモリ領域が増加し,巨大なデータを扱うことも可能となる.一方,複数GPUを利用する上で問題になる点として,GPU 間でのデータ通信がある.通常,GPUはPCI-Express によって接続されているが,ここの通信のメモリバンド幅が小さいため,ボトルネックになる可能性が高い.そのため,GPU 間でのデータの依存をできるだけ削減することが望ましい.提案手法では,GPU 間でのデータ通信の削減に加え,負荷分散を行ない処理の高速化を図った.さらに,複数GPU を持つノードからなるクラスタにおける手法も提案した.また,実験により,提案手法の性能を評価した.図が実験結果である.NVIDIA Tesla M2090を2台搭載した単一ノードの実験において,単一GPUを利用した場合に比べて最大2倍程度の高速化が実現できている.また,スペースの都合で割愛するが,複数ノードを利用した環境でも高速化が達成されることを示した.
-
ソフトウェアリポジトリマイニング

ソフトウェア開発の過程では,様々なデータがリポジトリと呼ばれるデータベースに蓄積される.このデータを活用し,ソフトウェア開発の支援に用いる研究を行なっている.
1つは,識別子名の命名を支援する手法の研究である.大量のソフトウェアのソースコードから,識別子名とその名前のついたプログラム要素に関連する情報の組を収集し,命名ルールと呼ぶデータベースを構築する.開発者が命名に悩んでいる状況と,命名ルールデータベースに存在する命名事例を比較し,類似した状況で使用されていた名前を推薦する.
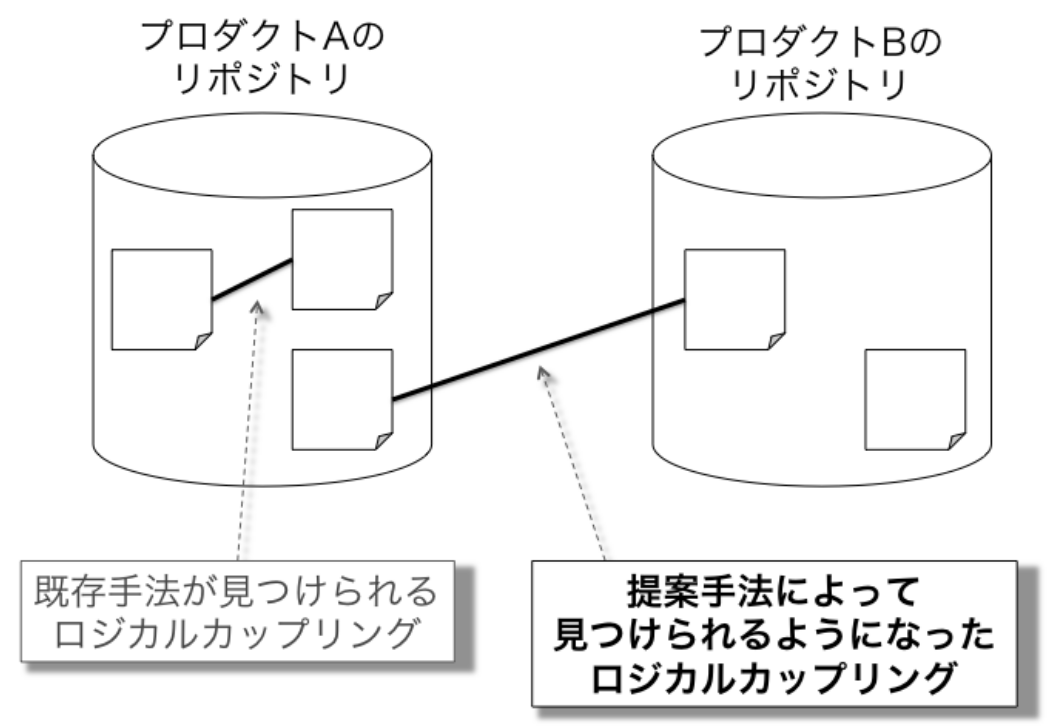
もう1つは,リポジトリを跨いだロジカルカップリング検出である.クラスやファイルが同時に変更される傾向をロジカルカップリングと呼び,ソフトウェア開発および保守の際に変更漏れを防止することや,ソフトウェアの構造を評価することを目的として利用されている.これまで研究されてきた手法では,同一のバージョン管理システムリポジトリの中に含まれる要素同士のロジカルカップリングのみを得ることができたが,複数のリポジトリを用いて開発が行なわれている場合にはその間ではロジカルカップリングを検出することはできなかった.そこで,いくつかの経験的ルールを用いることで,複数のリポジトリの間で同時に変更される傾向を発見する手法を提案した.実験の結果,ライブラリとそれを利用するプロダクトの間や,プロジェクトが分岐して派生したプロダクト同士の間にロジカルカップリングを発見することができた.
3)XML・Webプログラミング
-
XMLストリームに対するキーワード検索
本研究では,XMLストリームに対して,指定したキーワードが特定のパス式に含まれるような部分XMLデータを検索する手法を開発した.より具体的には,キーワード検索とXPathに基づく検索を合わせた検索を可能にする.本研究では,非決定性有限オートマトンを基にした手法を拡張して,パス式とキーワードを組み合わせた検索をXMLストリームに適用することを可能にした.
本研究の有効性を示すために,人工データと実データを利用して評価を行った.人工データとしては,XMark データセットを利用した.実データとしては,DBLPのXMLデータとMondialを用いた.実験では,検索精度(適合率および再現率)と性能(スループットおよびメモリ使用量)について評価を行った.既存研究のCKStreamと本研究を比較した結果を図に示す.精度については,既存手法,提案手法ともに問合せにマッチするべき結果がすべて抽出されている(b).一方,既存手法の適合率は不要な検索結果も抽出しているのに対し,提案手法では必要な検索結果だけを抽出できていることがわかる(a).性能評価では,単位時間あたりのデータ処理量(スループット:(d))では,既存手法よりも大きいサイズのデータを処理できている.また,メモリ使用量(c)は既存手法よりも少ないメモリ量で検索を実現している.

-
XMLに対するファセット検索
XMLに代表される半構造データは複雑な構造を持つため,問合せを正確に記述することは一般に容易ではない.構造が複雑になるほど,検索すべき情報がどこにあるかがユーザからわかりにくくなる.そのために,ユーザは適切な問合せを記述できず,所望する情報を得られない,といった状況に陥ってしまう.
この問題に対し,本研究では探索的検索手法であるファセット検索を適用する手法を開発した.ファセット検索は属性情報つきの実体に対して探索的検索を提供する検索手法である.そのため,本研究の先行研究では,ファセット検索を可能にするフレームワークを提案した.本研究では,このフレームワークを拡張し,より効果的なファセット検索システムを提供する.具体的には,(1)検索対象情報の導出の自動化,と (2)より複雑なXMLデータに対するファセット検索の適用を行う.まず,(1) では検索対象となりうる部分データを経験則的に判定するアルゴリズムを提案する.次に,(2) では (1)の経験則をネットワーク構造を許すデータに対しても適用する.ここで利用した経験則は次の二点である.一つ目は,頻繁に出現する構造は情報の単位を表し,安定的に頻出する構造ほど適切な情報であるという経験則である.二つ目は,構造の要素は意味的に理解可能な内容であるという経験則である.
提案手法の有効性を検証するために,(1) 自動的に抽出した情報を人手で検証,および (2) 実データへの適用し構築したインターフェースの検証を行った.ここでは,自動抽出した情報の抽出精度の評価結果を図に示す.実験には実際に利用されているXMLデータを九種類利用した.精度評価には人手で用意した正解情報をどの程度抽出できているかの度合いを表す適合率と再現率を用いた.実験結果から,適切なパラメータを設定することで正確に抽出できることがわかった.

-
LODに対するキーワード検索
Linked Open Data(LOD)とは,相互にリンクされたオープンデータのネットワーク(Web of Open Data)を構築し,機械処理可能なデータを広く公開しようとする試みである.近年のデータ公開の流れと相まって,政府や企業等がデータを公開する手段として注目されている.LODにおいて,データはResource Description Framework(RDF)によって記述され,URIにより相互に参照される.また利用者は,クエリ言語SPARQLを利用することで,問合せを行うことができる.今日LODは代表的な半構造データ情報源となりつつある.
しかしながら,SPARQL問合せを記述するために,利用者はSPARQL言語そのものを習得することが必要である.さらに,問合せ対象となるLODデータそのものの構造を知る必要がある.LODデータは一般に複雑なグラフ構造を持つため,複雑かつ巨大なデータの場合,特に後者は困難である.また,SPARQLの結果はランキングされていないため,重要度の高い結果を判別することが困難である.
この問題に対して,本研究ではLODに対するキーワード検索手法を開発した.関連研究において行われているような,RDFトリプルを単位とする検索ではなく,エンティティをベースとし,ObjectRankによるランキングを行う点に特徴がある.まず,LODデータにおける検索対象となるエンティティを与える.本手法では,システム構築者等によって事前に検索対象となるエンティティが指定されているものとする.検索対象となるエンティティが決まると,次に各エンティティに対応するサブグラフの抽出および特徴抽出を行う.得られたグラフ(エンティティサブグラフ)に対して,ObjectRankを適用することで,各エンティティに対する評価値を計算することができる.これにより,検索結果のランキングを行う.今年度は,DBPediaのデータを対象に,予備的な評価を実施し,提案手法が実際に有効であることを確認した.
今後は,実データによる評価を行うとともに,スキーマグラフにおけるエッジの重みの自動調整について検討する予定である.
-
LODに対するビューおよびLINQによる問合せ
一般に,LOD(Linked Open Data)は多様なドメインから構成される複雑なグラフ構造をもつ.さらに,複雑なグラフ構造への問合せを記述するには,RDFデータのグラフ構造を把握した上で,SPARQL問合せ言語による問合せを適切に記述する必要があり,一般の利用者に対して敷居が高いという問題がある.
これに対して,本研究の先行研究では,LINQ によるビューを用いた LOD に対する問合せ手法を提案した.この手法では,まず,公開対象のLOD をよく知る技術者が,それをどのような形式で公開したいかを JSON ビューの形式で記述する.このようにして提供された JSON ビューに対して,ユーザは LINQ 問合せ言語を利用して問合せを記述することで, LINQ 使用者は LOD に対する専門的な知識を必要とせずに LOD への問合せを行うことができる.
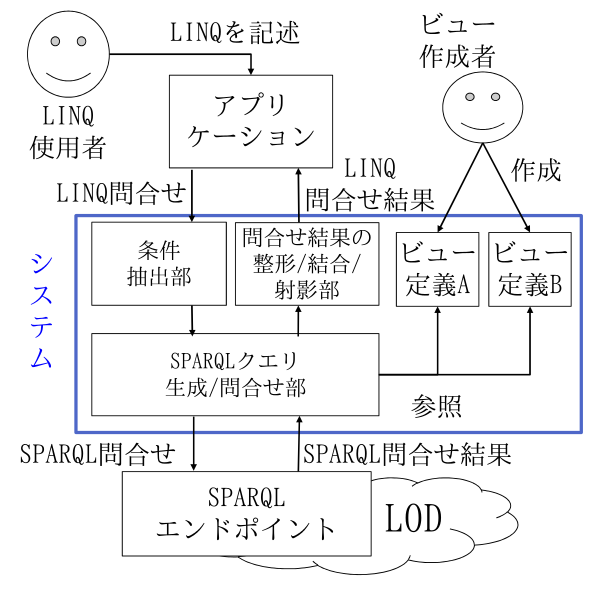
提案システムの概要図を右に示す.条件抽出部では,クエリを解釈する.問合せ条件に加え,結合条件,最終的な射影に必要な要素を抽出する必要がある.SPARQL生成/問合せ部では,問合せ条件とビュー定義からSPARQLクエリを生成し複数の問合せ先に問合せる必要がある.問合せ結果の整形/結合/射影部では,ビュー定義を使用してJSONを整形するだけでなく,条件抽出部で抽出した結合条件,射影に必要な要素を使用して,JSONを結合,最終的に必要な要素のみを射影する.
今年度は,JavaScript言語上のLINQ実装であるJSINQを対象に,プロトタイプシステムの実装を行った.今後は結合演算を含む問合せを本手法で行った場合と,直接エンドポイントに対して行った場合と,比較評価を行う予定である.また,コストベースの問合せ最適化についても検討を行う.
4)科学分野におけるデータベース応用
-
GPV/JMAアーカイブ
計算科学研究センター地球環境研究部門と共同で,気象庁気象予報データベース「GPV/JMAアーカイブ」(http://gpvjma.ccs.hpcc.jp)の開発,および管理,運用を行っている.GPV/JMAアーカイブは,気象庁が公開している気象予報グリッドデータ(GPVデータ)を蓄積するとともに,外部登録ユーザへのデータを提供することを目的としている.GPV/JMAアーカイブで提供しているデータは,全球モデル,メソスケールモデル,リージョナルスケールモデル,週間アンサンブル,月間アンサンブル,季間アンサンブルの6種類である.
-
格子QCDデータグリッドILDG/JLDG
Japan Lattice Data Grid (JLDG), International Lattice Data Grid (ILDG)は,格子QCD配位データを共有するためのデータグリッドである.計算科学研究センター素粒子物理研究部門と連解し,JLDG/ILDGの運営に継続参画している.
-
X線天体観測データにおけるアウトバーストの類似検索
ブラックホール,中性子星などはX線を発する天体として知られており,それらの天体には,短期間に大量のX線を放出する「アウトバースト」という現象が存在することが知られている.また,JAXA宇宙研海老沢教授らのグループにより,異なるX線天体の間で,アウトバーストのX線強度変化に類似性が見られることが近年明らかにされた.これは,背後にある物理過程の類似性を示す可能性があり興味深い.このため,海老沢教授らのグループと共同で,X線天体の観測データを対象に,類似したアウトバーストパターンを検索する手法を研究開発している.